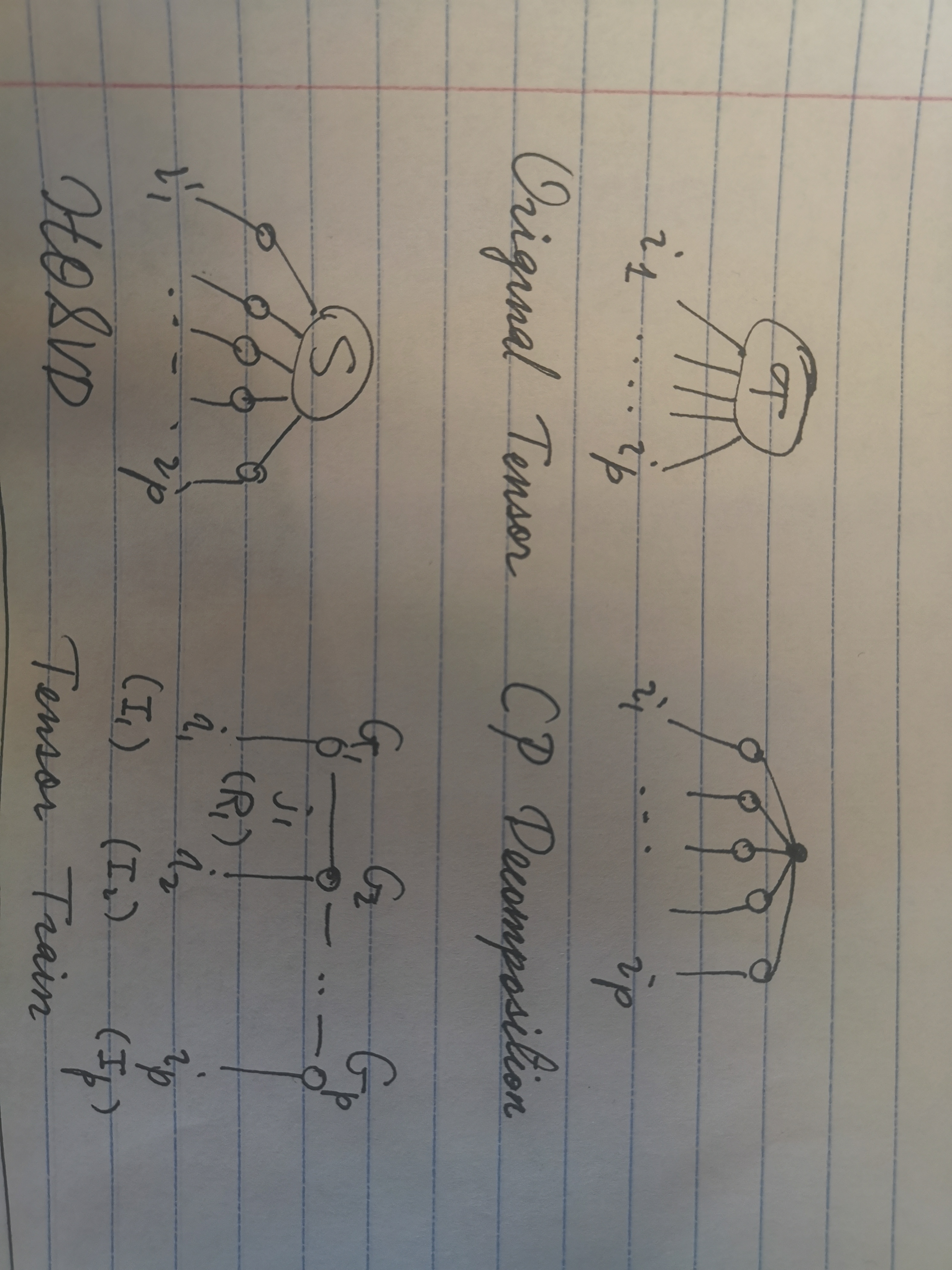
这次讲的基本上就是张量——张量积,张量的分解(CP-Decomposition, HOSVD)。之前我们处理矩阵,用的是SVD和eigenset的分解,动机是在低维上把握矩阵的行为,进而把握这些矩阵对应的高维数据集的性质。对于张量,很容易想到如法炮制。但是不幸的是,尽管矩阵的分解是一个相对容易的套路,张量的decomposition却是一个NP-hard的问题。
-
何为张量
有三种定义。
- free vector space中的等价类。——QM里面,用的是这个定义。我们在这个讲义里用的也是这个定义。
- basis变换时满足某种特定变换规则的对象。——GR里面我学到的就是这个。这也是我在课上唯一听懂的部分。
- “linearizer of multilinear maps”——一个数学家可能会喜欢的说法。与本课的内容和我的兴趣都无关。
对于我不幸的大脑来说,这些定义都太数学了。况且,我不像许多其他同学一样学过许多高明的量子场论。因此,在了解这些定义的具体内容之前,不妨先产生一个模糊的概念:张量是线性映射之间的线性映射。
-
第一个定义的解释
取n1,…,nk维欧氏空间V1,…,Vk,令F代表这些空间的cartesian积生成的所谓"free vector space",这就是说,Cartesian积得到的∑ni维空间中的每一个元素都是该空间的一个basis(现在,忘掉直和空间中的线性性)。一开始,我还以为V1×V2×…×Vk就是F呢。实际上,Cartesian Product弄出来的这东西叫直和,维数是∑ni;直积得到的空间,维数是∏ni。
令M是由形如
(x1,…,xi−1,xi+yi,xi+1,…,xk)−(x1,…,xi−1,xi,xi+1,…,xk)−(x1,…,xi−1,yi,xi+1,…,xk)
和
α(x1,…,xi−1,xi,xi+1,…,xk)−(x1,…,xi−1,αxi,xi+1,…,xk)
的元素构成的子空间。那么,直积V1⊗⋯⊗Vk就是商空间F/M。商空间的意思就是说,对于F中的元素F, f,F=f+m,m∈M,那么这两个元素属于同一个等价类,这些等价类的集合就是商空间。一个简单的例子。取V1,V2。他们的基是{vk},{wk}。V1×V2的基底是{(vi,0)+(0,wj)}。V1⊗V2的基底是{(vi,wj)}。
为什么说这个定义是QM里面采用的呢?在QM里面,量子态的直积满足以下性质:
ψ1⊗(ϕ1+ϕ2)=ψ1⊗ϕ1+ψ1⊗ϕ2;αψ⊗ϕ=ψ⊗(αϕ)=α(ψ⊗ϕ)
此处等号就表示属于同一个等价类。
-
第二个定义的解释
取V有基{e1,…,en},其对偶空间有{e∗1,…,e∗n} 满足 e∗j(ei)=δij。现在,我们旋转一下,将V的基换成e~k=∑i=1nAkiei。或者说,ei=∑k=1n(A−1)ike~k。
我们可以知道,e~∗ℓ=∑j=1n(A−1)jℓe∗j。对偶空间基底的变化是A的逆决定的。这种变化方式与V的基底的变化方式相逆,因此称这是逆变的。
对于V中向量v,
∑i=1n∑k=1nvi(A−1)ike~k=∑k=1nv~ke~k⇒v~k=∑i=1n(A−1)ikvi
其分量值的变化也是逆变的。
对于对偶空间中向量w的分量,自然是协变(与V的基底的变化方式协同)的:w~ℓ=∑j=1nAℓjwj。
因此,我们可以写出张量的分量的变化规律来:
t~ℓ1⋯ℓqk1⋯kp=(A−1)i1k1⋯(A−1)ipkpAℓ1j1⋯Aℓqjqtj1⋯jqi1⋯ip
考虑一个矩阵M,它是两个线性空间之间的线性映射。现在这两个空间的基底都旋转:
e~k=∑j=1nAkjej ; f~ℓ=∑i=1mBℓifi
如果我们把M的分量写成Mji的形式,M(ej)=∑i=1mMjifi,那么
M(e~k)=M(j=1∑nAkjej)=j=1∑nAkjM(ej)=j=1∑nAkj(i=1∑mMjifi)=i=1∑mj=1∑nMjiAkjfi=ℓ=1∑m(i=1∑mj=1∑n(B−1)iℓMjiAkj)f~ℓ
顺理成章。
因此,M的变换方式正是(1,1)张量的变换方式,M可以认为是W⊗V∗的一个元素了。
-
张量积空间的一些情形
V∗⊗W和W⊗V∗是一样的。这就是说,ij的前后顺序没什么关系。为了理解这个事实,我们引入张量积作为向量的写法,因为张量积空间是向量空间,这是很自然的。将两个向量的张量积记成:
a⊗b=⎝⎜⎜⎜⎜⎛a1ba2b⋮an1b⎠⎟⎟⎟⎟⎞
现在有线性映射A:V1→W1 and B:V2→W2。我们知道,A⊗B作用在V1中元素和V2中元素的张量积上,得到(A⊗B)(a⊗b)=(Aa)⊗(Bb)。在这种记号之下,
A⊗B=⎝⎜⎜⎜⎜⎛A11BA21B⋮Am11BA12BA22B⋮Am12B⋯⋯⋯A1n1BA2nB⋮Am1n1B⎠⎟⎟⎟⎟⎞
这是很令人满意的。这种矩阵运算也叫矩阵的Kronecker积。特别的,可以想见,取M=A⊗B,取A和B的standard basis(即cartesian basis),显然有
fi⊗e∗j=fi(ej)t
e∗j⊗fi=fi(ej)t
(根据W⊗V∗的意思,Mjifi⊗e∗j=M)
因此本节初提到的两个张量积空间是相等的。
-
张量的缩并
Tqp=V1⊗⋯⊗Vp⊗W1∗⊗⋯×Wq∗
取v(i)∈Vi,φ(j)∈Wj∗,定义线性映射Csr:Tqp⟶Tq−1p−1,那么映射
Csr(v(1)⊗⋯⊗v(p)⊗φ(1)⊗⋯⊗φ(q))=φ(s)(v(r))v(1)⊗⋯v(r^)⋯⊗v(p)⊗φ(1)⊗⋯φ(s^)⋯⊗φ(q)
是缩并映射。其中,带帽子的指标表示在直积中略去这一项。
-
张量的秩
张量积空间也是向量空间,所以张量积之间还可以继续张量积。取t∈Tqp,s∈Tsr,我们记
Tqp(t,s)×Tsr→Tqp⊗Tsr↦t⊗s
由上一节的结论,我们可以shuffle所有那些一维的向量空间,从而得到Tqp⊗Tsr≅Tq+sp+r。
授课者的remark:由此,我们可以建立张量代数T(V)=⨁p=0∞Tp(V),从而进入数学家熟悉的领域。
令t∈Tp=V1⊗⋯⊗Vp,那么定义张量秩
rank(t)=argminr{r∈N∣t=∑i=1rv(i)(1)⊗⋯⊗v(i)(p), where v(i)(j)∈Vj}
与矩阵秩意义差不多,都是用尽可能少的秩为一的分量刻画一个线性映射。所以说一个秩为一的(p,0)张量就是p个向量的张量积(用上一节的符号写下来,还是一个向量的样子)。
一般张量的秩的计算是NP-hard问题。常用的算法是CP(canonical polyadic) decomposition。我们之后会再提到它。张量的情况里,我们同样希望做低秩的近似。有一种叫Kruskal记号的,是这样做的:λ∈Rk,U(n)∈RIn×k,i=1,…,p,记
[λ;U(1),…,U(p)]≡∑j=1kλju(j)(1)⊗⋯⊗u(j)(p)
In是一个数列,表示每个U矩阵的行数。每个U矩阵都有k列,并且规定它们全是l2-norm为1的。u(j)(i)就是第i个U矩阵的第j列。一般来说,固定k,Y∈V1⊗⋯⊗Vp,其中dim(Vn)=In。然后我们找具体的λ和U,使得Y≈X≡[λ;U(1),…,U(p)]。比如说我们熟悉的SVD就可以写成[σ;U,V]。
这里约等于的意思还不明确。我们通过定义张量上的距离来解决这个问题。例如,Frobenius内积
⟨t,s⟩F=∑i1,…,ipti1…ipsi1…ip。
-
Tensor Embedding of Vectorial Data
量子力学里面,人们关心张量积,是因为想要分解一个复杂系统的波函数,分离出它的自由度来。固体物理最近的一些进展使得人们产生了如下的想法:把n维欧氏空间的数据点表示成张量ti1⋯ip,那么
y^=wii⋯ipti1⋯ip
就是一个predictor。这个weight tensor元素太多,一般是通过分解成低秩张量来近似求解。据这课的老师讲,那些固体物理学家盯上了一个叫TT decomposition的东西,原理是把高秩的w压缩成一些矩阵,减少需要优化的参数的数目。
还有另外一个故事(思路),这就是把张量积空间当做是普通的线性空间,然后用我们熟悉的线性空间的工具来处理。例如,考虑一个embedding
(xy)↦(cos4πxsin4πx)⊗(cos4πysin4πy)∈R2⊗R2
考虑一个如下图左上角的数据
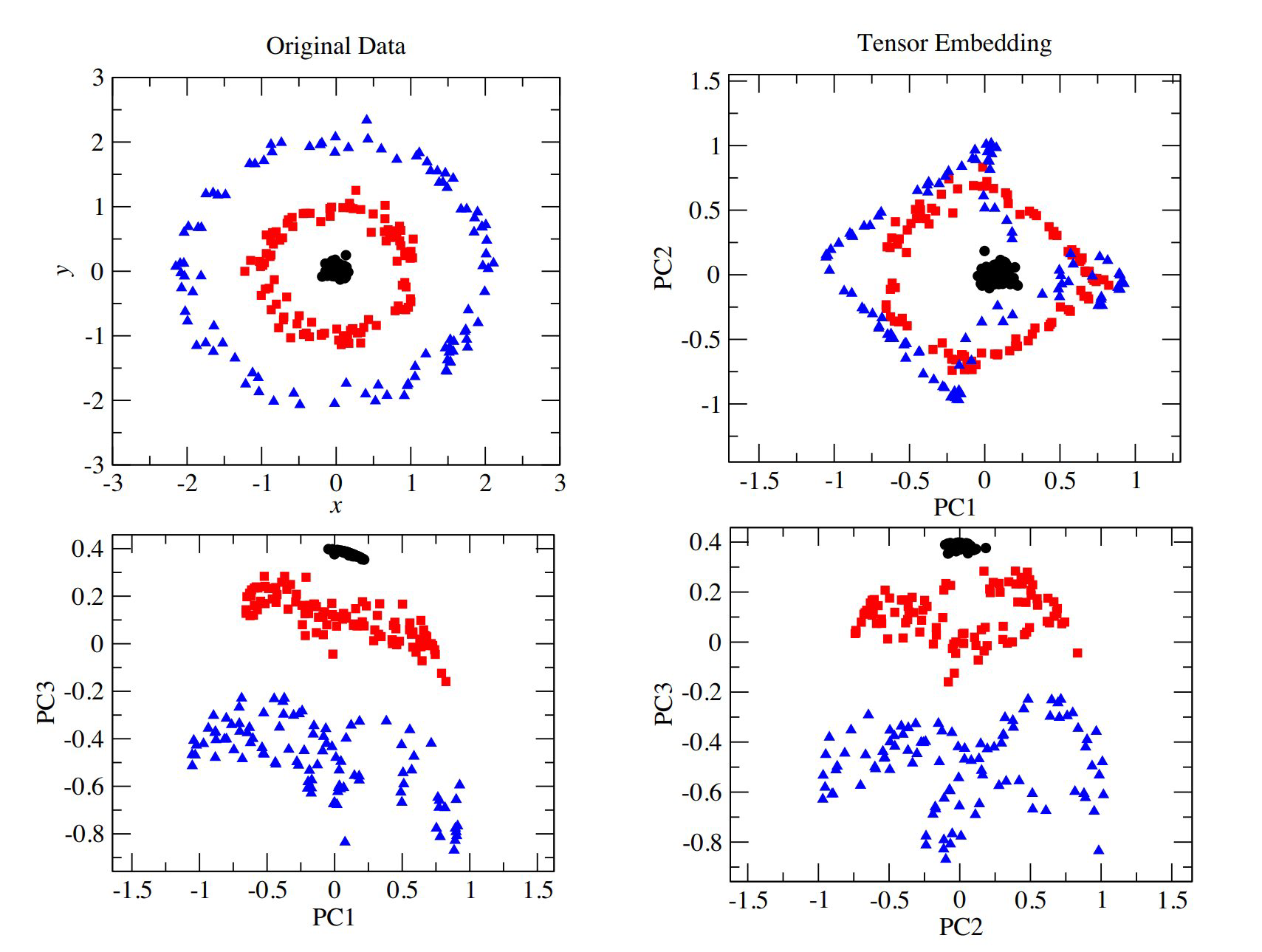
x值接近0的点会产生向量(10),而x∼±1的点会产生(0±1)。y也一样。如图下方,在张量积第1,3个分量的图中,这些点恰当地分开了。
-
Symmetric and Alternating tensors
令πp是置换群。取其元素σ,作用在Tp(V)的分量上,
σ(t)=tiσ(1),…,iσ(p)ei1⊗⋯⊗eip
如果∀σ∈πp,σ(t)=t,那么就说这个tensor是symmetric的;如果∀σ∈πp,σ(t)=sign(σ)t,那就是alternating的。所有(p,0)的symmetric 的张量的集合写作Symp(V) 或Sp(V),alternating的则写作⋀p(V)。
-
什么是tensor unfolding
取t∈V1⊗⋯⊗Vp。在分量记号下,ti1⋯ip所有n-th index的集合叫做第n个模。例如,取
t=(142536)
那么第一个模就是行指标1,2,第二个模就是列指标1,2,3.
然后,固定一个mode,变化其他所有的指标,得到的就是mode-n fibre。比如说,
令t∈V1⊗⋯⊗Vp,Ii是Vi的维数。那么t的mode-n unfolding/matricization/flattening 就是一个In×(∏i=nIi)维的矩阵,记做t(n),其中原张量分量ti1⋯ip被map到矩阵的第in行,j列,其中
j=1+∑ℓ=1,ℓ=np[(iℓ−1)Jℓ]
Jℓ=⎩⎪⎨⎪⎧∏m=ℓ+1n−1Im,1,∏r=1n−1Ir∏s=ℓ+1pIs,ℓ≤n−2ℓ=n−1ℓ≥n+1
**这玩意到底是什么意思?**我到现在也不知道。这种充满指标的公式对我来说是不可理解的。我只能拿一个性质当做定义来理解,即
X(n)=vn(vn+1⊗⋯vp⊗v1⊗⋯vn−1)t
所以说,行数是指标in决定的,而至于每一列怎么排,那就是先紧着in+1排,然后是in+2,一直到ip,再是i1,然后再到in−1。根据我看到的资料,这个顺序好像不是什么物理意义之类的东西决定的,而是Fortran的习惯。
-
n-mode product
X∈V1⊗⋯⊗Vp,A=W⊗Vn∗,那么矩阵A从张量(把它想象成一个高维数阵立方体)的第n个维度上乘过去,就是
Y≡X×nA=C1n(X⊗A)
从这个角度想,Y=X×nA⟺Y(n)=AX(n)就是显然的了。如果Y=X×1U1×2U2×3⋯×pUp,那么flattening就可以相应地写成Y(n)=UnX(n)(Un+1⊗⋯⊗Up⊗U1⊗⋯⊗Un−1)t。
-
CP decomposition
这玩意叫canonical,主要原因是它是从tensor rank的定义出发的。但是实际上哪怕是对矩阵这种低阶张量的分解也不是这样做的:我们是做SVD,动用一个稀疏的“core tensor”或者说singular value matrix,来分担这个矩阵在空间上多么“椭”的信息,而不是拿几个矩阵乘积加权求和去得到原矩阵(这种做法相当于使用identity作core tensor)。
CP decomposition唯一的优势是它简单。算法上,它是这样做的:首先,定义Khatri-Rao product
A⊙B=(A;1⊗B;1⋯A:,K⊗B:,K)
现在有Y∈V1⊗⋯⊗Vp,想拿X=[λ;U(1),…,U(p)]去套它,判断标准采用frobenius norm。我们首先固定所有的U,只留一个U(n)来优化。为了方便起见,采用unfolding出来的矩阵,这样比较好处理:
X(n)=U(n)Λ(U(n+1)⊙⋯⊙U(p)⊙U(1)⊙⋯⊙U(n−1))t
解minA∥∥∥∥Y(n)−A(U(n+1)⊙⋯⊙U(p)⊙U(1)⊙⋯⊙U(n−1))t∥∥∥∥F2
令A=U(n)Λ,B=(U(n+1)⊙⋯⊙U(p)⊙U(1)⊙⋯⊙U(n−1))
那么就可以用MP伪逆求得
A(BtB)=Y(n)B⇒A=Y(n)B(BtB)+
那么,λ就是A的每一列的模,U(n)就是A的每一列归一化之后得到的矩阵。
如此这般,先随机搞一批U,然后一个一个地优化。这个方法很令人不舒服,因为它是ill-posed的,不能保证收敛。
-
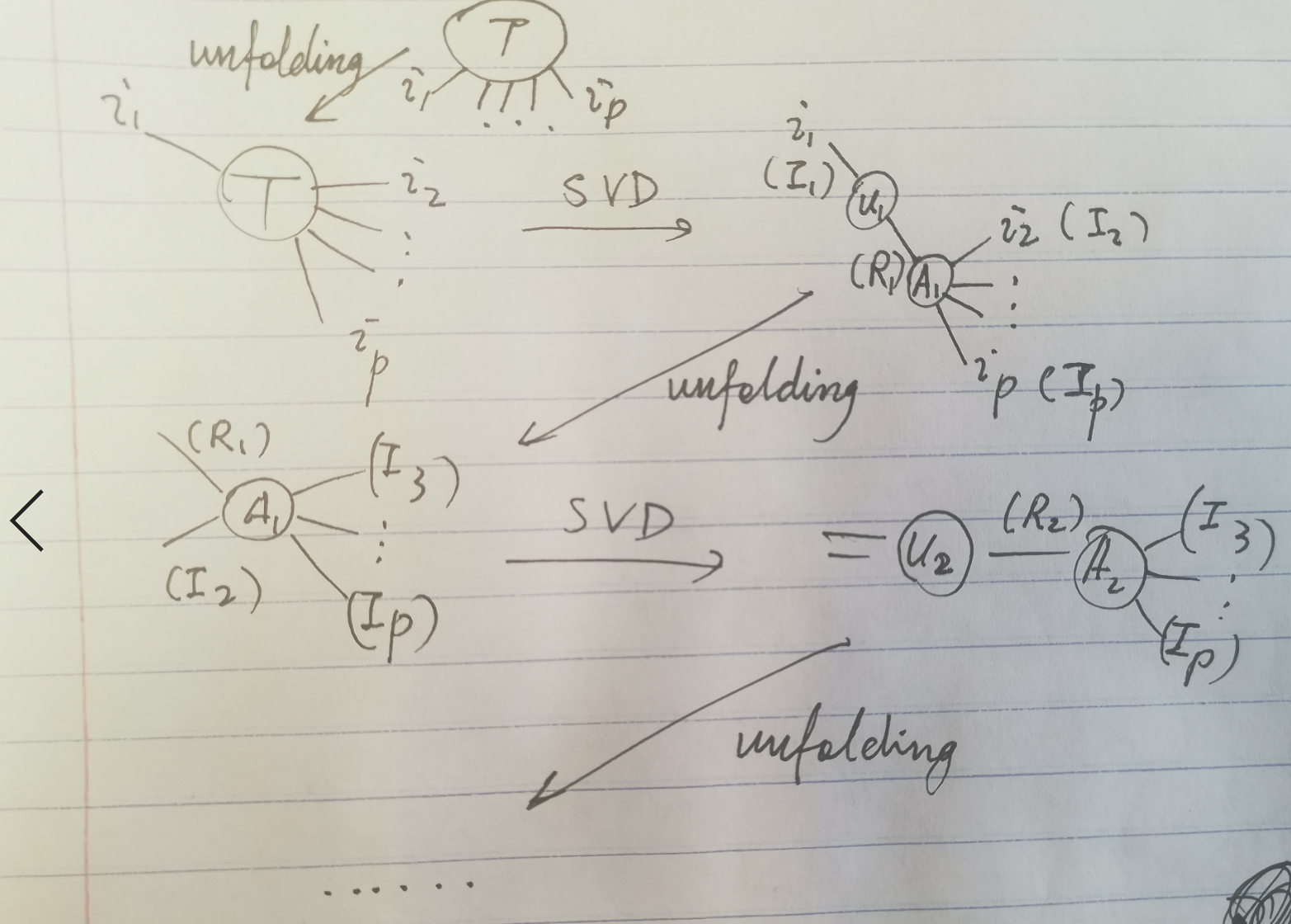
HOSVD(high order SVD)
这是低维的SVD在高维的推广,也叫tucker decomposition,但tucker本人只是搞了三维的情况。现在令In是每个Vn的维数,那么X∈V1⊗⋯⊗Vp≡Tp可以被分解成
X=S×1U(1)×2U(2)⋯×pU(p)
比如说,对于一个矩阵,M=Σ×1U×2V。
我个人理解这个S是sparse,不是singular。可能是因为我从来就没理解singular value这个名字到底啥意思。sparse不仅是说S“只有对角元”,也说明这个新东西参数少。还是拿矩阵的SVD来说,本来T的维数是m×n,现在有k≪m,n个奇异值,那么只需要k(m+n−1)≪mn个参数就能刻画整个矩阵。
这个S也满足矩阵的奇异值分解的诸般性质。比如
- U(n)=(U(1)(n)⋯U(In)(n))是In×In的正交矩阵;
- ∀n∈{1,…,p},⟨Sin=α,Sin=β⟩F=0 for α=β,S的“列”互相正交;
- ∥∥∥Sin=1∥∥∥F≥⋯≥∥∥∥Sin=In∥∥∥F≥0,S的“列”可以排序。
怎么求这个分解呢?我们可以对unfolding得到的矩阵做SVD:
X(n)=U(n)Σ(n)V(n)t
顺手排序:
σ1(n)≥σ2(n)⋯≥σIn(n)≥0
然后用这个U(i)定义
S=X×1U(1)t×2U(2)t⋯×pU(p)t
这样就都求出来了。这样得到的结果自然满足以上性质,例如后两条(第一条是平凡的)
S(n)=U(n)tX(n)(U(n+1)t⊗⋯⊗U(p)t⊗U(1)t⊗⋯⊗U(n−1)t)t=U(n)tX(n)(U(n+1)⊗⋯⊗U(p)⊗U(1)⊗⋯⊗U(n−1))=Σ(n)V(n)t(U(n+1)⊗⋯⊗U(p)⊗U(1)⊗⋯⊗U(n−1))
从这里能看出来,那一串U是正交变换,所以S的orthogonality是V决定的,V自然满足这性质。然后∥∥∥Sin=1∥∥∥F=σ1(n),以此类推,所以排序必然成立。这样,所有性质都满足。
-
TTSVD
所谓Tensor Train SVD,指的是把张量的每个分量用一连串矩阵相乘的形式表示的操作。附图中,TTSVD的记号长得像一列火车,因此得名。我对这个东西的理解不是很好,所以简要记之,以后再想。
A(i1,i2,…,ip)=G1(i1)G2(i2)…Gp(ip)
其中Gk(ik) 是 Rk−1×Rk的一族矩阵(换句话说,Gk是一个VRk−1⊗VRk⊗VIk的张量)。由“边界条件”,r0=rp=0。算法是这样的:从i1这维度unfold,做SVD,然后得到U1,这是一个1×I1×R1的数阵。接着,对SVD右面的ΣV部分做unfolding,同时unfoldr1和i2两个维度,再做SVD,得到U2,这是一个(R1×I2)×R2的矩阵……通过这种方式,我们就可以从U得出G来。